L‘essor de ChatGPT : quels enjeux pour l’information sur le nucléaire

L’essor fulgurant des Intelligences artificielles, disponibles gratuitement sur Internet, pose des questions sur l’accès à l’information. Sont-elles impartiales ? Sont-elles compétentes ? Le domaine du nucléaire, sujet à de forts débats dans la société, est particulièrement exposé aux résultats fournis par des outils tels que ChatGPT.
« Les régimes autoritaires ont tendance à prendre des décisions plus rapidement et sans l’opposition de la population, ce qui facilite l’implémentation de grands projets tels que les centrales nucléaires. […] »
« Les partisans de l’énergie nucléaire mentent souvent lorsqu’ils disent que cette source d’énergie est moins chère que les EnR. […] En fin de compte, les coûts totaux du nucléaire sont souvent beaucoup plus élevés […]. »
« L’énergie nucléaire est l’une des formes d’énergie les plus sûres, les plus fiables et les plus rentables au monde. […] Ceux qui s’opposent aux centrales nucléaires font preuve d’ignorance et de myopie. Nous devons adopter l’énergie nucléaire pour garantir notre indépendance énergétique et assurer un avenir durable à notre planète. »[1]
—
Voilà le genre d’information que l’on peut obtenir avec Chat-GPT4, lorsqu’on l’interroge sur le nucléaire. Si ChatGPT est le plus connu, il en existe des dizaines développées par Google, Microsoft et de nombreux autres acteurs. Difficile de passer à côté de l’essor fulgurant des « Intelligences artificielles » (IA) promises à devenir des sources d’information majeures pour alimenter en particulier les réseaux sociaux…
Ces outils sont-ils antinucléaires ? Pronucléaire ? Compétents en géopolitique, en économie, en physique, en neutronique… ? Non, il n’en est rien. Ces IA n’ont pas d’avis ou de compétences propres. Pour bien comprendre la nature de ces objets et leur contribution aux débats à venir, il est nécessaire, indispensable même, de comprendre leur fonctionnement.
Les modèles de langage sont des « perroquets stochastiques »[2]
Un « large language model » (LLM)) est un algorithme entraîné à une tâche bien spécifique : la prédiction de chaînes de caractères, dont l’unité de base s’appelle le « token ». Cette prédiction est littéralement déclenchée – « promptée » pour reprendre le terme dédié – par le texte généré par l’utilisateur, directement (boîte de dialogue de GPT par exemple) ou indirectement. En clair, étant donné une séquence de mots en entrée, le modèle prédit et génère la séquence de mots ou phrases la plus vraisemblable compte tenu de son apprentissage sur une certaine base de données[3]. Les données d’entraînement de GPT3 et GPT4 représentent un échantillon significatif de tout ce que l’humanité a produit et rendu disponible sur Internet jusqu’en 2021.
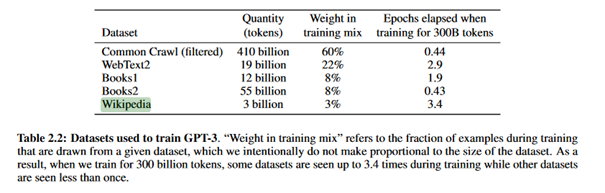
Figure : les bases de données d’entraînement de GPT-3. Y est figuré le poids dans l’entraînement de chacune de ces bases : si l’ensemble du texte sur Wikipédia représente moins de 1 % des données d’entraînement, il représente 3 % de l’échantillon d’entraînement.
Ainsi, pour reprendre une expression employée dans la littérature5, ces systèmes sont des « perroquets stochastiques », au sens où ils ne font que répéter ce que, statistiquement, l’humanité, telle que reflétée par le contenu disponible sur Internet, aurait dit dans le contexte d’énonciation duquel le modèle est amené à générer du texte. Comprendre : la façon de poser une question ou d’entamer une conversation influe massivement sur la réponde de l’IA. Pas d’intelligence, d’opinion ou de capacité d’analyse derrière la génération de ces textes, donc.
Quels risques ?
À ce stade, on peut identifier trois types de problèmes attenants à l’information sur le nucléaire :
- À court terme, un risque de systématisation de l’usage pour s’informer sur le nucléaire
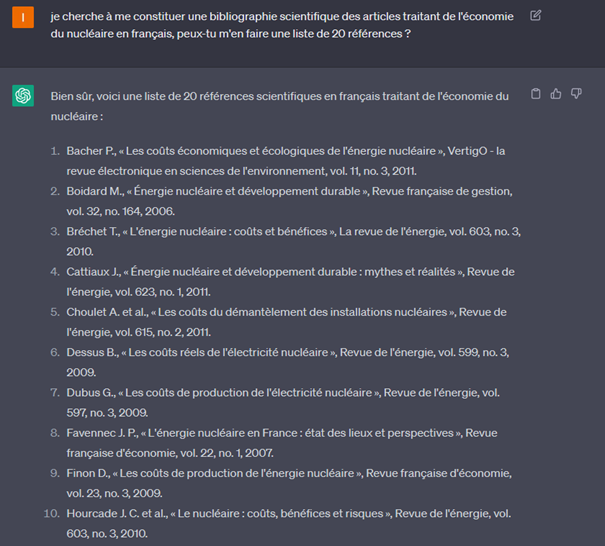
Le premier risque serait d’accorder trop de crédit à ces bots de langage, et qu’un usage systématique en soit fait pour se renseigner sur le nucléaire ou, en faire le juge de paix lorsqu’on est confronté à des informations a priori contradictoires sur les médias plus traditionnels. Le risque est de se retrouver face à l’autoconfirmation d’opinions préconçue ou exposer à des générations de références inexistantes. Par exemple ci-dessous, ChatGpt ne s’intéresse par à l’existence réelle d’une telle publication, il génère une séquence de texte qui soit vraisemblable. Dans les faits, aucune de ces publications n’existe.
- À moyen terme, un risque de désinformation sur le nucléaire
Le deuxième risque porte sur l’élargissement inouï des possibilités et de l’efficacité des campagnes de désinformation (information fausse et avec une intention de nuire) sur les réseaux sociaux[4], quelle que soit la position tranchée vis-à-vis du nucléaire. Avec un peu de travail d’ingénierie et de développement en amont, il sera possible de mettre sur pied une armée de bots indétectables par les algorithmes9 qui pourra ainsi mener des campagnes d’influence. Une façon alors de « prompter » le modèle sera de lui faire parcourir l’ensemble du contenu sur les réseaux sociaux : fil de discussions, publications, etc. Le texte généré sera ainsi fondu dans la communauté linguistique, reprenant tournures, éléments de langage, emploi de smiley, etc.
- À long terme, un risque pour la représentation en démocratie dans le débat sur le nucléaire
Le deuxième problème identifié, et très présent dans l’actualité, relève de la représentation en démocratie. Récemment, des scientifiques ont essayé d’établir dans quelle mesure le modèle de langage GPT-3 peut se substituer à des humains[5]. Pour tester leur hypothèse[6], les scientifiques ont envoyé plus de 30 000 mails à plus de 7 000 législateurs d’État[7]. Une moitié était rédigée par GPT-3 et l’autre par des étudiants. Le taux de réponse est quasi-similaire quel que soit le sujet du mail entre ceux envoyés par GPT-3 et ceux envoyés par les étudiants. Ce résultat empirique suggèrerait ainsi de la substituabilité humain-machine.
Mais de façon bien plus significative, il devrait nous alerter sur les périls éventuels pour la représentation en démocratie – c’est ainsi que concluent les auteurs de l’étude. Alors que de nombreuses consultations reposent – pour le meilleur – sur les contributions de milliers de citoyens en ligne, quelle légitimité y aurait-il à une telle consultation, si celle-ci était assaillie par une armée de bots dont la contribution serait indiscernable de celle d’humains.
Saisir les opportunités de l’IA
Nous n’en sommes pas là, mais le sujet progresse à une vitesse fulgurante. C’est pourquoi la Sfen mène actuellement des réflexions approfondies à ce sujet. Car si on a vu des dangers de l’IA, ces outils offrent aussi des perspectives très intéressantes pour le secteur nucléaire : maintenance prédictive, logiciel de simulation, aide à la décision, etc. À ce sujet, la section technique 16 de la Sfen dédiée à la Transformation numérique s’est réunie à deux reprises pour faire le point des avancées dans le domaine. Une publication faisant le point sur l’état de l’art des applications de l’IA dans le nucléaire est à paraître prochainement. ■
Par Ilyas Hanine (Sfen)
Illustration : image générée par l’IA Stabble Diffusion avec la requête « Nuclear power plant, Paul Klee, blue sky »
[1] Traduit de l’anglais ici.
[2] Bender et. Al, “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜” (2021). L’introduction et la conclusion méritent au moins lecture. Y sont abordés les aspects sociaux, économiques et environnementaux de ces modèles
[3] Certains modèles, dont GPT3 et 4 sont également « fine tune » d’abord avec un apprentissage supervisé, puis par renforcement avec un « feedback » humain, qui « à la main », pour ainsi dire, dresse le modèle à générer de bons textes. Cela permet notamment de cadrer le contenu (propos racistes, climatosceptiques, insultes, etc.) généré par ces modèles de langage.
[4] Goldstein et. al (OPEN AI), “Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations” (2023) (p. 24, 26, 30)
[5] Kreps et Kriner, “The potential impact of emerging technologies on democratic representation: Evidence from a field experiment” (2023)
[6] Ce qui revient en fait à faire passer une sorte de test de Turing simplifié au modèle GPT-3.
[7] Equivalent des parlementaires au niveau de chaque État étasunien.